■ 딥러닝과 컴퓨팅 파워
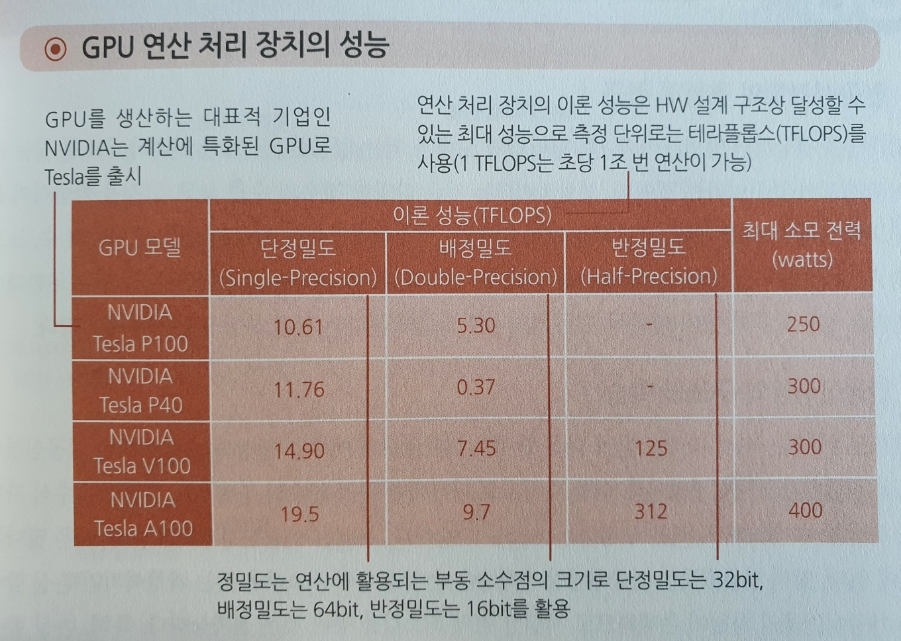
GPU는 수천 개의 코어로 구성된 연산장치로 2009년부터 본격적으로 부상하였고 이론적인 성능은 같은 가격의 CPU 보다 약 10배 이상 높은 반면 메모리 전송이 많은 알고리즘에서는 성능이 급격히 떨어진다. 그러나 2012년 이미지 인식 경진대회에서 우승한 AlexNet 알고리즘이 GPU에 특화된 인공신경망을 구성하여서 딥러닝에 최적화된 자원으로 주목받았고 이는 현재까지 이어지고 있다.
구글은 딥러닝 전용 하드웨어인 텐서 연산 처리 장치 TPU를 개발하여 GPU 보다 전력소모를 8배 감소시켰고, 인공신경망 자체를 하드웨어로 구현한 뉴로모픽 칩 (Neuromorphic Chip)의 개발은 세계적인 관심을 받고 있다.
■ 인공신경망의 학습과 최적의 모델
최적의 인공신경망 모델을 도출하기 위해 거의 무한대에 가까운 경우의 수를 학습해야 한다. 이는 딥러닝이 이론적으로 정립된 방법론이라기보다는 귀납적인 성향에 가깝기 때문이다. 인공신경망의 구조는 선행 연구를 분석하여 선정하는 것이 일반적이고, 대부분의 시간은 적절한 입력 데이터를 선정하기 위한 수집 및 가공 등에 소비된다.
■ 인공신경망의 가중치와 설명 가능성
딥러닝에서 인공신경망을 수식으로 나타낼 경우 가중치의 의미를 설명하기가 어렵다. 특히 수백만 개의 가중치를 갖는 심층신경망에서는 짐작조차 어렵다. (딥러닝의 예측 성능은 뛰어나지만 어떻게 그런 결과가 도출되었는지에 대한 설명력은 떨어진다)
인공신경망의 구조를 이론적으로 해석하고 의미를 부여한다면 현대 과학은 한 단계 발전할 수 있는 가능성이 있다.

■ 좁은 인공지능과 범용 인공지능
현재의 인공지능은 전이 학습이 어려워 학습한 내용에만 최적화된다는 한계가 있다. 범용 인공지능의 출현을 전문가들은 짧게는 10년 내, 길게는 100년까지 예상한다. 전자의 이유는 딥러닝의 고도화로 전세계적인 연구의 집중이 인공지능의 발전을 가속화한다는 것이고, 후자는 현재의 인공지능 역시 불완전하므로 새로운 패러다임 전환이 필요하다는 것이다.
** 딥러닝은 막대한 규모의 데이터를 투입해야 쓸모가 있다는 점에서 사람의 접근 방법과 거리가 있다. 그래서 개인적으로는 위에서 말하는 후자가 설득력이 있다고 본다. 딥러닝이 아닌 새로운 인공지능 기법이 나와야 되지 않을까 생각한다.
'AI_머신러닝_딥러닝' 카테고리의 다른 글
| 딥러닝 최신 용어정리 #6 메타학습 원샷학습 지속적인학습 신경망구조탐색 AutoML (0) | 2022.09.16 |
|---|---|
| 딥러닝 최신 용어정리 #5 스타크래프트2의 인공지능 알파스타 (0) | 2022.09.12 |
| 딥러닝 최신 용어정리 #3 전처리 개인정보 알고리즘 편향 지속적인 학습 등 (0) | 2022.09.07 |
| 딥러닝 최신 용어정리 #2 CNN GNN 강화학습 과적합 등 (0) | 2022.09.05 |
| 딥러닝 최신 용어정리 #1 퍼셉트론 엣지 손실함수 등 (0) | 2022.09.05 |