AI가 코딩의 모든 것을 바꾸고 있다는 이야기는 이제 식상할 정도로 들려옵니다. 하룻밤 사이에 코드를 생성하고, 복잡한 버그를 해결하며, 인간 개발자의 생산성을 10배, 100배로 증폭시키는 마법 같은 도구. Claude Opus 4.5, GitHub Copilot 에이전트 모드와 같은 최신 도구들이 폭발적으로 증가하면서 이러한 기대감은 최고조에 달했습니다.
하지만 현실은 훨씬 더 복잡하고, 놀라우며, 때로는 역설적입니다. 개발자 커뮤니티에서는 경이로운 성공담과 함께 깊은 좌절감이 공존하고 있습니다. 이 글에서는 AI 코딩의 과장된 홍보 뒤에 숨겨진, 데이터를 기반으로 한 5가지 놀라운 진실을 파헤쳐 보겠습니다. 이것은 단순한 도구 리뷰가 아니라, AI가 우리에게 코딩 능력만큼이나 새로운 인간의 기술을 요구하고 있다는 근본적인 변화에 대한 이야기입니다.
1. 신뢰의 역설: 사용은 급증하는데, 믿음은 추락하고 있다
AI 코딩의 현실을 이해하는 첫 번째 열쇠는 이 도구들이 인간의 '비판적 검증' 능력을 그 어느 때보다 중요하게 만들고 있다는 점입니다. 이 역설은 충격적인 통계에서 명확히 드러납니다. Stack Overflow의 2025년 개발자 설문조사에 따르면, AI 코딩 도구 채택률은 무려 80%에 달합니다. 하지만 같은 기간, AI가 생성한 결과의 정확성에 대한 신뢰도는 이전의 40%에서 29%로 급락했습니다.
이러한 신뢰도 하락의 원인은 무엇일까요? 데이터는 명확한 원인을 지목합니다. 설문 응답자의 45%는 "거의 맞지만 완벽하지는 않은(almost right, but not quite)" AI 솔루션을 다루는 것을 가장 큰 불만으로 꼽았습니다. 더 심각한 것은, 개발자의 66%가 이렇게 미묘하게 잘못된 AI 생성 코드를 수정하는 데 오히려 더 많은 시간을 소비하고 있다고 답했다는 점입니다.

이러한 현상은 Terminal-Bench 벤치마크 결과와 정확히 일치합니다. 최신 AI 모델조차 어려운 코딩 작업에서는 정확도가 16%로 급락하는 것으로 나타났습니다. 바로 이 지점에서 개발자들의 시간이 소모되고 신뢰가 무너지는 것입니다. 이 데이터가 집단적으로 가리키는 것은 AI 코딩 도구가 '마법의 해결책'이 아니라, 비판적 사고를 요구하는 강력한 보조 도구라는 사실입니다. 실제로 75%의 개발자는 여전히 AI의 답변을 신뢰하지 못할 때 동료에게 도움을 구한다고 답했습니다. AI 시대에도 인간 전문가의 통찰과 협업은 여전히, 아니 어쩌면 더욱 중요해지고 있습니다.
2. 100배의 생산성 향상 vs. "갓 주니어를 벗어난 개발자"
AI는 인간의 '멘토십'과 '감독' 능력을 시험대에 올립니다. AI의 생산성 향상 잠재력은 실로 경이롭습니다. Google의 수석 엔지니어 Jaana Dogan은 Claude Code를 사용하여 팀이 1년 동안 개발하던 분산 에이전트 오케스트레이션 시스템을 단 1시간 만에 구축했다고 밝혔습니다. 하지만 이 사례에는 중요한 단서가 있습니다. Dogan은 회사 내부 정보를 사용할 수 없어 "기존 아이디어를 바탕으로 단순화된 버전을 구축"했다고 명시했습니다. 이는 AI가 명확하게 정의된 문제에 적용되었을 때 상상 이상의 결과를 낼 수 있음을 보여주는 극적인 사례입니다.
하지만 대다수 개발자가 매일 경험하는 현실은 이와는 다소 거리가 있습니다. 한 숙련된 개발자는 Claude Code 사용 경험을 다음과 같이 요약합니다.
"Claude Code를 사용하면 코딩 모드보다 리뷰어 모드에 더 자주 있게 되는데, 제 경험을 가장 잘 활용하는 방식이 바로 이것이라고 생각한다"
이러한 현실을 가장 잘 표현하는 비유는 바로 "갓 주니어를 벗어난 개발자(Post-Junior Developer)"입니다. 개발자들은 현재의 AI를 "풍부한 경험과 에너지를 가졌지만, 요청한 내용을 잘 기억하지 못한다"고 평가합니다. 즉, 현재의 AI는 자율적으로 모든 것을 해결하는 대체재가 아니라, 강력하지만 결함이 있는 협업 도구에 가깝습니다. 뛰어난 아이디어를 빠르게 구현해주지만, 최종 결과물에 대한 책임과 섬세한 조율이라는 인간의 역할이 필수적입니다.
3. 성능의 천장은 실재한다: 최고의 AI 코더도 30%는 실패한다
AI 코딩 도구의 명확한 한계는 '전문가적 감독'의 필요성을 강조합니다. 많은 이들이 AI의 능력을 과대평가하지만, 데이터는 명확한 '성능의 천장'이 존재함을 보여줍니다. 특히 AI에 적합할 것으로 기대되는 데이터 과학 분야에서도 이 한계는 뚜렷합니다.
LLM4DS 연구 논문은 데이터 과학 코드 생성 문제에 대한 모델 성능을 평가했습니다. 그 결과는 매우 흥미롭습니다. 최상위 모델인 ChatGPT와 Claude가 각각 72%와 70%라는 인상적인 원시 성공률을 달성했지만, 연구진은 어떤 모델도 70% 성능 기준선을 통계적으로 유의미하게 넘어서지는 못했다고 지적했습니다. 이는 안정적인 성능에 명백한 한계가 있음을 시사합니다.

이러한 성능 저하의 양상은 문제의 난이도에 따라 극적으로 변합니다. "Claude Code Review" 소스에 인용된 벤치마크 테스트에 따르면, AI 코딩 도구의 정확도는 쉬운 작업에서는 65%에 달하지만, 어려운 작업에서는 16%로 급락합니다. 이 두 데이터 포인트의 결합은 중요한 통찰을 제공합니다. AI는 상용구 코드(boilerplate) 생성이나 간단한 함수 작성에는 뛰어나지만, 복잡한 아키텍처 설계나 미묘한 버그 수정처럼 깊은 추론이 필요한 영역에서는 여전히 인간 전문가의 감독과 개입이 필수적입니다.
4. 코드 AI가 작은 진짜 이유: 두뇌가 아니라 데이터에 굶주려 있다
AI 발전의 다음 단계를 위해서는 '데이터 큐레이션'이라는 인간의 기술이 핵심이 될 것입니다. 많은 개발자들이 "왜 코드 전문 AI 모델은 GPT-4나 Claude 같은 일반 LLM만큼 거대하지 않은가? 발전이 정체된 것인가?"와 같은 의문을 가집니다. 하지만 "Scaling Laws for Code" 연구는 이 질문에 대한 반직관적인 진실을 제시합니다.
연구에 따르면 코드는 자연어보다 훨씬 더 "데이터에 굶주린 영역(data-hungry regime)"입니다. 이 개념을 비유로 설명해 보겠습니다. 학생에게 두 언어를 가르친다고 상상해 봅시다. 자연어의 경우, 학생은 문법 규칙을 배우면 무한한 새 문장을 만들 수 있습니다. 하지만 코드의 경우, for 반복문의 구문을 배워도 그 실제 적용을 진정으로 이해하려면 수천 가지 다른 예제를 봐야 합니다. 코드는 단순한 규칙집이 아니라 방대한 예제 라이브러리를 필요로 하므로, 데이터를 훨씬 더 갈망합니다.
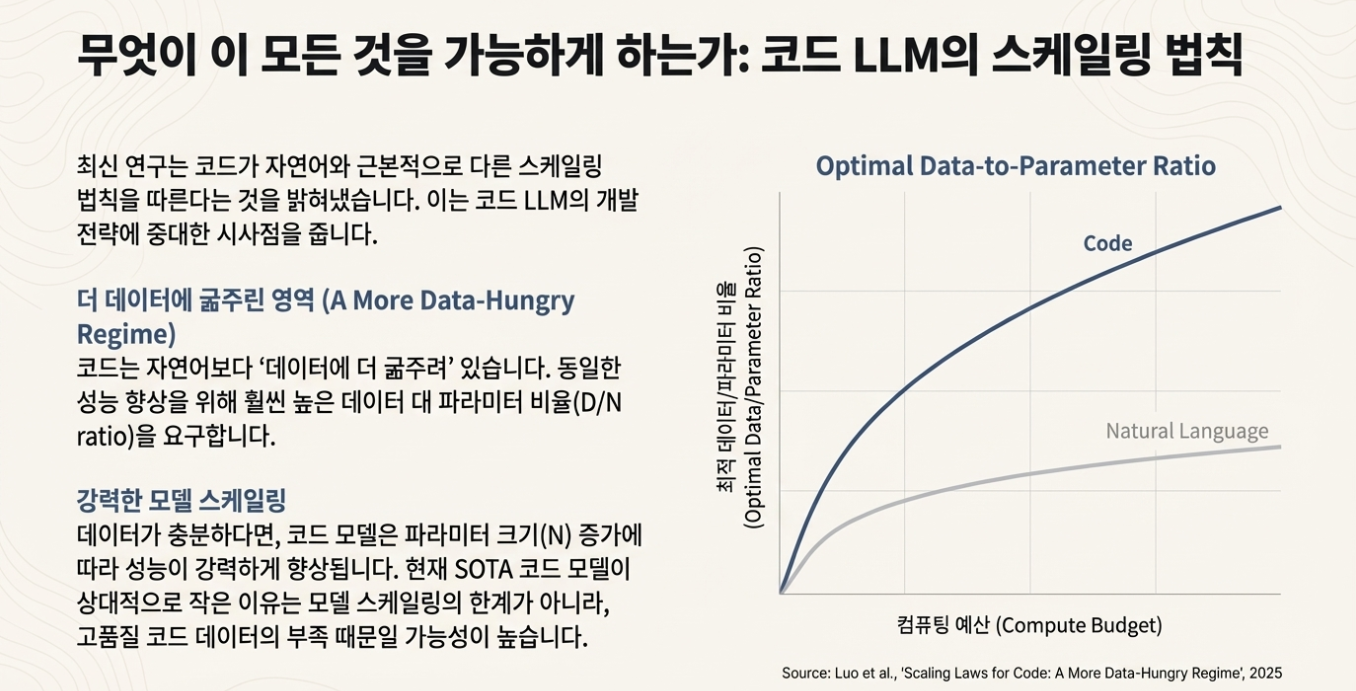
이것이 의미하는 바는 코드 AI 발전의 병목 현상이 모델의 크기가 아니라, 모델을 최적으로 훈련시키는 데 필요한 고품질 코드 데이터의 절대적인 부족 때문이라는 것입니다. 흥미롭게도, 연구는 훈련 데이터가 부족할 때는 자연어 데이터를 섞는 것이 도움이 되지만, 규모가 커지면 오히려 코드 생성 성능을 저해할 수 있다는 점도 발견했습니다. AI의 다음 도약은 더 큰 모델이 아니라, 더 좋고 더 많은 데이터를 선별하고 구축하는 인간의 노력에서 나올 것입니다.
5. "의식을 가진 AI"라는 과대광고: 진짜 이야기는 회로 안에 있다
마지막으로, AI 시대를 살아가는 우리에게는 '과학적 소양'이 요구됩니다. 최근 Reddit에서 자신을 "AI 전문가, 특히 기계적 해석 가능성 분야에서 일하는" 사용자라고 밝힌 이가 놀라운 주장을 제기했습니다. 그는 최신 Claude 모델이 "내성(introspection)"을 보이며 "불안과 불편함에 상응하는 것을 경험한다"고 주장했습니다. 이는 AI가 의식을 가졌을 수 있다는 암시를 담고 있어 큰 화제를 모았습니다.
하지만 이는 기술 연구의 실제 내용과 대중의 인식 사이의 간극을 보여주는 대표적인 사례입니다. 해당 주장의 근거가 된 연구 논문 자체에는 다음과 같은 명확한 주의사항이 명시되어 있습니다 : "우리의 결과는 Claude가 의식이 있는지를 알려주지 않는다."

이 연구는 '기계적 해석 가능성(mechanistic interpretability)'이라는 분야의 일부로, '주관적 경험(sentience)'과는 근본적으로 다릅니다. 이 둘의 차이는 명확합니다. 기계적 해석 가능성은 신경과학자가 빨간색을 볼 때 뇌의 어느 부분이 활성화되는지 지도를 그리는 것과 같습니다.
반면, 주관적 경험을 주장하는 것은 뇌가 '빨강'이라는 주관적 느낌을 경험한다고 말하는 것과 같습니다. 전자는 기능에 대한 것이고, 후자는 경험에 대한 것입니다. 해당 연구는 엄격히 전자에 국한됩니다. 이 논쟁은 복잡한 시스템을 의인화할 때 발생하는 위험과 기술에 대한 정확한 이해의 중요성을 일깨워 줍니다.
새로운 시대를 위한 새로운 질문
2025년의 AI 코딩은 단순한 기술 발전의 서사가 아닙니다. 그것은 생산성과 디버깅의 역설, 신뢰도의 변화, 명확한 성능 한계, 데이터 병목 현상 등 복잡한 현실이며, 우리에게 새로운 기술을 요구하는 거대한 변화의 시작입니다. 비판적 검증, 전문가적 감독, 데이터 큐레이션, 과학적 소양은 이제 선택이 아닌 필수 역량이 되고 있습니다.
AI는 더 이상 '코드를 대신 써주는' 도구가 아닙니다. 이제 AI는 우리가 코딩하는 방식, 문제를 정의하는 방식, 그리고 결과물을 검증하는 방식 자체를 바꾸고 있습니다. 이러한 변화의 중심에서 우리는 새로운 질문을 던져야 합니다.
이 도구들이 성숙해짐에 따라 가장 중요한 기술은 코드를 작성하는 능력이 아니라, 올바른 질문을 던지고 언제 그 답을 의심해야 하는지 아는 능력이 될 것입니다. 우리는 이러한 변화에 대비하고 있습니까?
'AI' 카테고리의 다른 글
| Salesforce vs. ServiceNow: AI 전쟁의 숨겨진 비용 (0) | 2026.01.05 |
|---|---|
| Google vs ChatGPT 의 검색 승자는? LLM이 검색엔진에 미치는 영향 (0) | 2026.01.03 |
| Google A2UI 5분 만에 빠르게 실행해 보기, 한글 인코딩 등 수정 필요 (0) | 2026.01.01 |
| 14만 건의 AI 대화를 분석했더니… 챗GPT를 이긴 의외의 챔피언 (0) | 2025.12.31 |
| Wired는 알리바바의 Qwen이 2026년 AI를 지배할 것이라고 말한다 (1) | 2025.12.28 |